
In light of IMTF’s recent partnership with Babel Street, we’re diving into the importance of accurate name matching in regulatory compliance and the complexities involved in screening names across different languages.
Key Takeaways:
- When names serve as one of the most critical data points in regulatory compliance, the different ways of writing a name can lead to significant challenges.
- Name matching for Chinese scripts and ideographs is particularly challenging due to complex characters, phonetic variations, name order differences, abbreviations, and cultural nuances.
- Adding to the complexity, different languages share the same script. Chinese, Japanese, and Korean all share the Han script, making differentiation between these languages a delicate process.
- Using simplistic name matching methods leads to inaccuracies. Fuzzy name matching is a technique that uses machine learning to identify and match names that are similar but not identical.
- Fuzzy name matching uses different algorithms, all with their own limitations, especially when applied to non-Latin scripts.
- IMTF partner Babel Street developed the two-pass hybrid method that minimizes limitations of one approach with the strengths of another, achieving better precision, recall, and accuracy.
- Siron One, powered by Babel Street’s advanced Name Matching technology, supports Han and 24 other scripts, enabling customers to manage complex scenarios to effectively combat financial crime and streamline their global compliance processes.
Verifying the names of customers and entities is one of the most fundamental steps in onboarding, KYC, and AML/CFT for all financial and non-financial institutions. Regulatory bodies globally require businesses to screen names against sanctions lists and watchlists, while Financial Intelligence Units depend on verified names to investigate financial crimes.
However, name screening, while integral to compliance processes, is highly complex. The quality, accuracy, and speed of name screening directly impact the risk, effort, and cost associated with key compliance functions such as KYC and AML.
Unlike unique numeric identifiers such as Social Security Number or numeric and biometric identifiers like Aadhaar numbers, names can be written in myriad ways and are not unique to a person or entity. Names can vary due to phonetic spelling, nicknames, shortened forms, misspellings, hyphens, titles, cultural differences, translations, transliterations, aliases, truncated names, semantic similarities, and even different name order conventions in databases.
When names serve as the most critical data point, these variations can create significant challenges. Yet for globally operating financial institutions, accurate cross-language name screening is vital for KYC/AML compliance. This process requires recognizing names in their original scripts and accounting for all possible translations and transliterations in other languages.
The Complexity of Name Matching with Chinese Scripts and Ideographs
Name matching for Chinese scripts and ideographs presents unique challenges due to the complexity of characters, phonetic variations, name order differences, abbreviations, and cultural nuances. In the Chinese language, each character has a unique meaning and pronunciation, which makes string-based structuring inefficient.
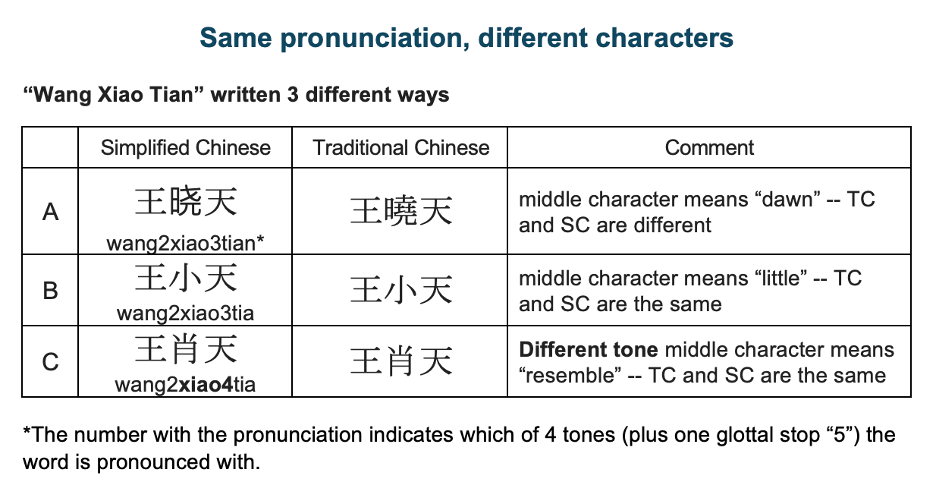
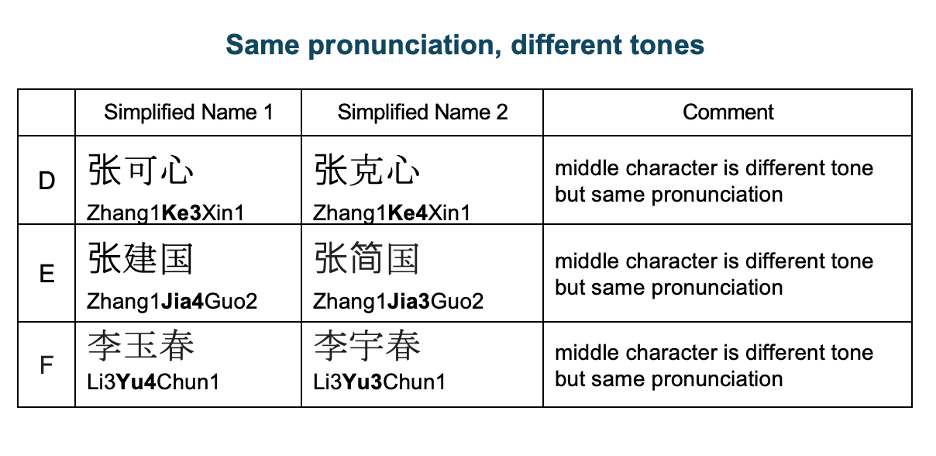
Chinese characters can be Romanized (e.g., Pinyin) in different ways, leading to significant phonetic variations. Additionally, culturally, Chinese names are typically written with the surname first, are often abbreviated, and may appear as nicknames or simplified characters. Besides, the same characters can have different meanings and pronunciations based on context.
To add to the complexity, different languages share the same script. Chinese, Japanese, and Korean all share the Han script, making differentiation among them challenging, especially when the language of origin is unknown. For example, while written Korean primarily uses Hangul, it also incorporates traditional Chinese characters (referred to as Hanja in Korean, Hanzi in Chinese, and Kanji in Japanese), which are represented and pronounced differently in each language.1
Even within one language, the way names are transliterated varies. For instance, transliterating a foreign name to Japanese would often use the phonetic Katakana instead of the ideographic Kanji.2
These complexities underscore the need for name-matching tools capable of understanding Han scripts, identifying the starting language of a name, and ensuring accurate translation and transliteration.
What is Fuzzy Name Matching
In different parts of the world, ID documents might use local languages, whereas banking documents use English. For screening against a watchlist, names have to be matched against Latin scripts. However, simple Romanization (transliteration into Latin scripts) is too simplistic, as names can be transliterated in many ways. Some languages lack some sounds and would be transliterated differently. For example, Chinese Cantonese lacks a distinct “R” sound, and the closest equivalent is “L”.
Using simplistic methods leads to inaccuracies, increasing false positives and negatives and risking reputational damage, whereas manual sorting and screening drive up compliance costs significantly.
Fuzzy name matching is a technique that uses machine learning to solve the above problems by identifying and matching names that are similar but not identical. It addresses issues like spelling variations, misspellings, and formatting inconsistencies. For example, it can recognize that “Jon” and “John” are likely the same name.
Fuzzy name matching for Chinese scripts and ideographs specifically needs to consider phonetic and structural similarities as well as contextual understanding.
Fuzzy Name Matching Techniques and Their Drawbacks
Fuzzy name matching can use different algorithms that can be customized to solve for specific types of name variations and errors. Below are a few of the common ones3:
- Edit Distance Algorithms
These measure the number of actions required to transform one name into another and are used in Levenshtein Distance, Damerau-Levenshtein Distance, Jaro Distance, Jaro-Winkler Distance, and Hamming Distance.
Drawback: These methods give equal weight to all changes/swaps without considering cultural nuances, and their application is limited to Latin names.
- Phonetic Matching or Common Key
This focuses on matching the sound of names with different spelling, like “Sara” vs. “Sarah”. A few common key methods include Soundex, Metaphone, Double Metaphone, and NYSIIS (New York State Identification and Intelligence System).
Drawback: This technique is better suited to Latin names. Precision decreases significantly for non-Latin scripts.
- List Method
Compares a name against all possible variations within a predefined list.
Drawback: A brute-force method of comparing each component of a name against all possible variations is time consuming and inefficient.
- Statistical or String Similarity Method
These assess the similarity of names using statistical measures, like the frequency or occurrence of characters or patterns. Some string similarity methods include Cosine Similarity, Jaccard Similarity, Dice Coefficient (Sørensen-Dice Index), and TF-IDF (Term Frequency-Inverse Document Frequency).
Drawback: While these methods render precise results in cross-language applications, they require training and adjustment, making them slower for dynamic applications.
- Word Embedding Method
This uses vector representations of names, words, or phrases, where similar words are closer to each other. It uses contextual and semantic variations and relations between words.
Drawback: Best suited for organization name matching rather than personal names.
In addition to these, there are other fuzzy name matching techniques such as token-based algorithms, deep-learning models using neural networks, and even domain-specific algorithms that account for special abbreviations and different naming conventions.
The Two-Pass Hybrid Method for Better Precision, Recall & Accuracy in Fuzzy Name Matching
To overcome the limitations of individual approaches, IMTF partner Babel Street employs a two-pass hybrid method. This approach combines the strengths of multiple techniques to achieve higher precision, recall, and accuracy in name matching.
For example, the common key method is first used for broad recall, narrowing down possible matches by transliterating names where necessary. These results are then refined using statistical methods to improve precision and filter the strongest matches.
The benefit of the statistical method is that it relies on linguistic variations in each language and not mass name generation like the list method. It can also compare names in different scripts, which cannot be done in the edit distance method.3
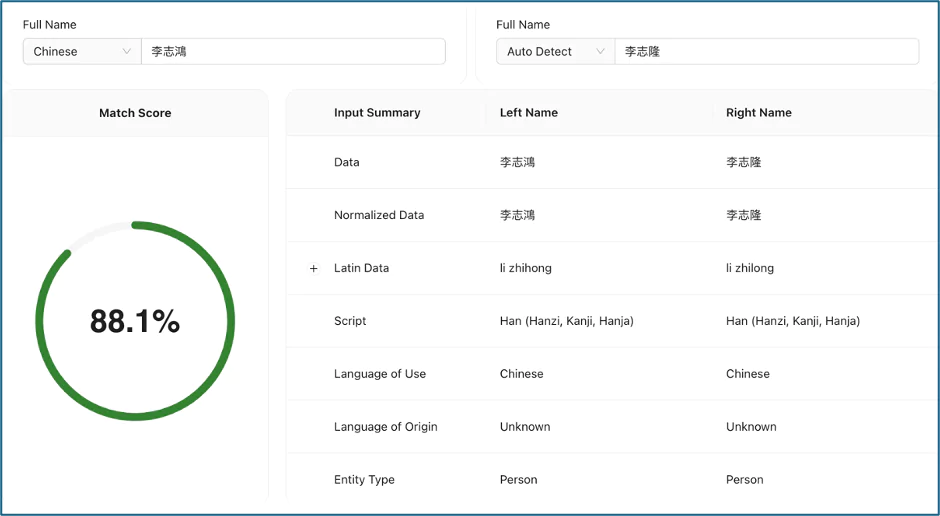
In the context of AML or fraud, name screening using whatever method needs to be fast, accurate, and reliable. It must work with an existing matching system to quickly narrow down possible matches and score the results – with the best matches having the highest score – thereby reducing the need for manual remediation.4
How Siron®One and Babel Street Solve Name Screening Challenges
Equipped with Babel Street’s advanced Name Matching technology, Siron®One supports 24 languages across multiple scripts, including Han scripts. The system accurately identifies the starting language of names and handles complex scenarios, such as translating Latin-based names into Japanese equivalents using deep learning neural networks.5
This integration highlights the strength of IMTF’s collaboration with Babel Street, reflecting a shared commitment to innovation and client-centric solutions.
By addressing the complexities of name screening with precision and efficiency, IMTF empowers clients across APAC and beyond with cutting-edge tools to meet evolving compliance and fraud prevention needs.
Read more about the partnership.
In the coming weeks, IMTF will interview fuzzy name matching expert, Gil Irizarry, CIO at Babel Street. Stay tuned to explore the challenges of fuzzy name matching for Chinese and non-Latin scripts and how to overcome them.
Contact us to learn more or to get a demo of our solutions.
Sources:
- https://www.babelstreet.com/blog/fundamentals-of-understanding-translating-and-matching-chinese-japanese-and-korean-names
- https://www.babelstreet.com/blog/why-japanese-transliteration-of-foreign-names-is-complex
- https://www.babelstreet.com/blog/fuzzy-name-matching-techniques
- https://www.babelstreet.com/blog/pairwise-name-matching-reduces-manual-compliance-remediation
- https://www.babelstreet.com/blog/deep-learning-brings-fuzzy-english-to-japanese-name-matching-into-focus


